Every application we create requires a place to store its data. In almost all cases, we use MariaDB, a modern fork of MySQL. We have found it to be excellent in terms of performance, reliability, simplicity and compatibility. However, there is one area in which this classic relational database does not excel compared with the many NoSQL options now available, and that is replication and resilience.
In this post we will discuss how we configure MariaDB multi-source replication in order to achieve redundancy, both on-site and off-site. We use MariaDB, but this guide will include the commands for both MySQL and MariaDB.
Throughout this guide, we will assume that there will be 3 servers in our cluster. It's not important where these servers are located, but in our configuration, we have 2 servers at our primary data centre, and a third server off-site. The cluster is built in a star configuration, so a single server is chosen as the primary, and the other servers are secondary.
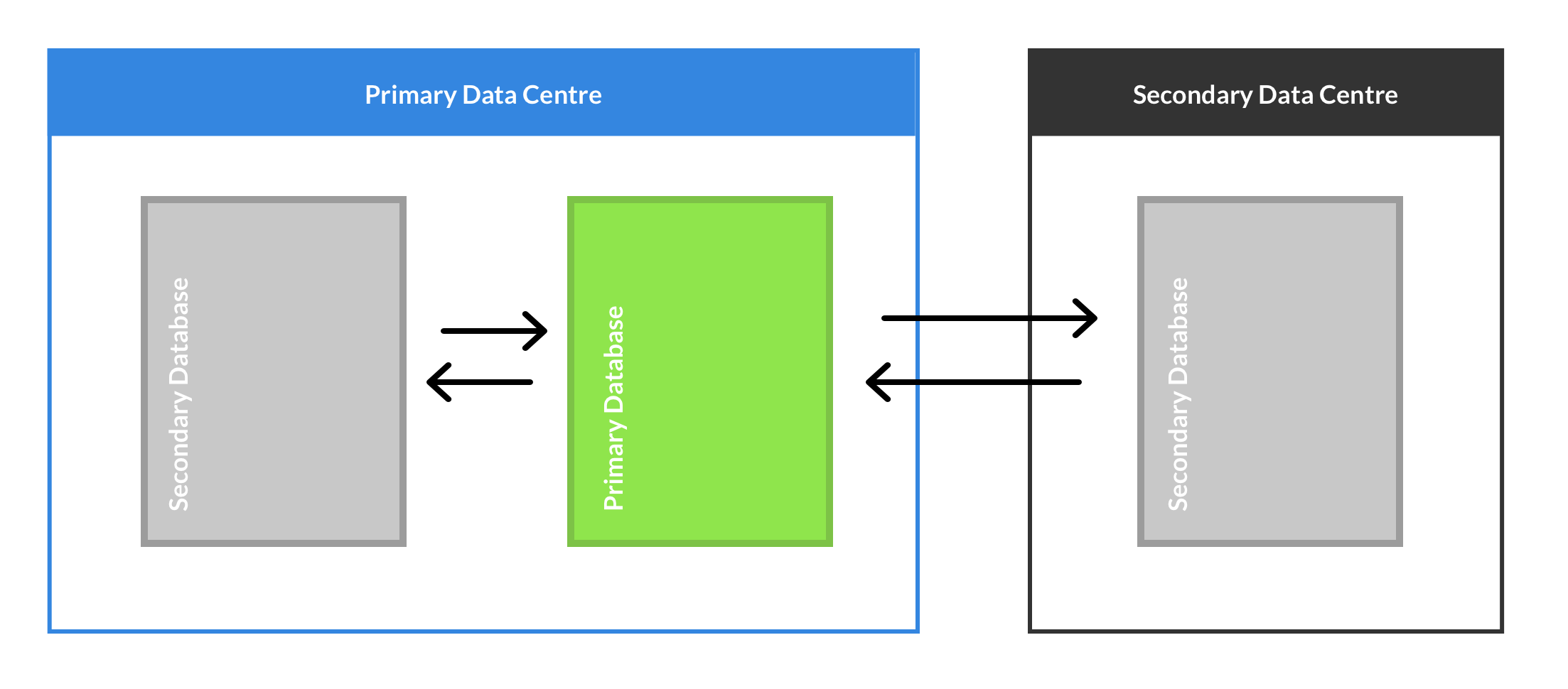
This configuration uses asynchronous replication, which means that all 3 servers can accept writes at any time, but there is no guarantee that these writes will be immediately reflected on the other servers. For this reason, we only use a single server at once, treating the cluster as an active-backup configuration.
Starting with a single MySQL server
This configuration starts with a single MySQL server. This can be a new server, but you can also start with an existing server containing data, and the process is exactly the same. As always, if you are working with existing data, we would strongly recommend taking a backup before getting started.
primary-server:~$ mysqldump -u root -p > mysql-backup-2017-03-27.sql
Next we will configure this server to be a MySQL master. A few lines need to be added or changed in the MySQL configuration file as follows. If any of these lines already exist, they should be updated, else they should be added somewhere within the [mysqld] section.
Each server needs a unique ID, this is the first server so we will use ID 1
server-id = 1
Most of our applications use auto-increment fields, so we need to ensure that 2 different servers never generate the same ID. This is achieved by incrementing IDs by 3, and giving each server a slot for IDs it generated. For example, the first server might generate IDs 1,4,7,10 and the second server would generate IDs 2,5,8,11.
auto_increment_increment = 3
auto_increment_offset = 0
The following directives cause the server to log all row updates, and store these logs for 10 days. These are the logs which will be streamed to the other servers in the cluster to keep them up to date.
log_bin = /var/log/mysql/log-bin
log_bin_index = /var/log/mysql/log-bin.index
binlog_format = row
expire_logs_days = 10
Finally, because this will be the primary server, we instruct it to keep the logs that are sent to it by slaves. This means that updates coming from one slave can be passed along to the others.
log_slave_updates
It is necessary to restart the database after making these changes. This is an inconvenience when working with an existing database but can't be avoided at this stage.
primary-server:~$ sudo /etc/init.d/mysql restart
We need to create a replication slave user. This user allows secondary servers to authenticate in order to start streaming changes. Be sure to generate a strong password to control this access.
primary-server:~$ mysql -u root-p
MariaDB/MySQL [(none)]> GRANT REPLICATION slave ON *.* to 'repslave'@'%' identified by 'PUT_A_SECURE_RANDOM_PASSPHRASE_HERE';
This server is now ready to be the first server in the cluster.
Prepare a secondary server
The secondary server must begin as a clean install of MariaDB or MySQL. Any existing data on this server will be lost. You should try to use the same version for all servers as far as possible, but minor differences are usually not problematic.
First, we will configure the new server in a similar manner to the primary. There are a number of differences from the primary server configuration. We must disable log_slave_updates on secondary servers, as well as remembering to increment the server-id and auto-increment-offset. We will also disable log_bin to save disk space during the initial replication, this will be re-enabled later.
server-id = 2
auto_increment_increment = 3
auto_increment_offset = 1
#log_bin = /var/log/mysql/log-bin
#log_bin_index = /var/log/mysql/log-bin.index
binlog_format = row
expire_logs_days = 10
#log_slave_updates
As before, restart the database to ensure these changes take effect.
secondary-server:~$ sudo /etc/init.d/mysql restart
Initial replication to secondary
We are now ready to replicate all data from the primary server to this secondary. This step is necessary even if there was no data on the primary server to begin with, and ensures that the servers begin in a 100% identical state.
First, create a MySQL dump on the primary server. The options passed to mysqldump ensure several things. Firstly they ensure that the data represents a consistent snapshot of the data, and secondly, that the binary log starting position is included with the dump. We will need this data shortly.
primary-server:~$ mysqldump --all-databases --flush-logs -q --master-data=1 --single-transaction -u root -p > mysql-replication-dump-2017-03-27.sql
Next we copy this dump to the secondary server, and import it into the new database instance there.
secondary-server:~$ scp primary-server:mysql-replication-dump-2017-03-27.sql mysql-replication-dump-2017-03-27.sql
secondary-server:~$ mysql -u root -p < mysql-replication-dump-2017-03-27.sql
If you have SSH keys set up and a large data set, this initial replication can be automated into a single step:
primary-server:~$ mysqldump --all-databases --flush-logs -q --master-data=1 --single-transaction -u root -pROOTPASSWORDHERE | ssh secondary-server "mysql -u root -pROOTPASSWORDHERE"
When this process is complete, shut down the database on the secondary.
secondary-server:~$ sudo /etc/init.d/mysql stop
At this point we need to make 2 small configuration changes. First, we re-enable log_bin on the secondary.
log_bin = /var/log/mysql/log-bin
log_bin_index = /var/log/mysql/log-bin.index
Ubuntu and Debian use a randomly generated password to allow its init scripts to manage its local database installation. Because our new installation is a 100% clone of the primary, we need to copy this password over. First, get the password from the primary server, and copy it into the configuration file on the new secondary server, replacing the password found there.
primary-server:~$ sudo cat /etc/mysql/debian.cnf
secondary-server:~$ sudo nano /etc/mysql/debian.cnf
Start the secondary database with its new configuration.
secondary-server:~$ sudo /etc/init.d/mysql start
Beginning the streaming replication (primary to secondary)
We are now ready to begin streaming replication from the primary to the secondary. This is all configured on the secondary. First we need to find the binary log starting position. This can be determined by looking in the file /var/lib/mysql/master.info.
secondary-server:~$ sudo head -n3 /var/lib/mysql/master.info
This will give us an output similar to the following. The first line can be ignored, the second line is the name of the master log file (MASTER_LOG_FILE), and the third line is the position in this file (MASTER_LOG_POS).
33
log-bin.003541
370
We will now begin the replication using the information above. Be sure to fill in all values MASTER_HOST with the IP of the primary server, the MASTER_PASSWORD we generated earlier, and the MASTER_LOG_FILE and MASTER_LOG_POS above.
MariaDB
secondary-server:~$ mysql -u root -p
MariaDB [(none)]> CHANGE MASTER 'primary' TO MASTER_HOST='XXXXXX', MASTER_USER='repslave', MASTER_PASSWORD='XXXXXX', MASTER_LOG_FILE='XXXXXX', MASTER_LOG_POS=XXX;
MariaDB [(none)]> start slave 'primary';
MySQL
secondary-server:~$ mysql -u root -p
MySQL [(none)]> CHANGE TO MASTER_HOST='XXXXXX', MASTER_USER='repslave', MASTER_PASSWORD='XXXXXX', MASTER_LOG_FILE='XXXXXX', MASTER_LOG_POS=XXX for channel 'primary';
MySQL [(none)]> start slave for channel 'primary';
If everything has worked, data should now be streaming from the primary to our new secondary. The status can be verified using the following command:
MariaDB
MariaDB [(none)]> show slave 'primary' status\G
MySQL
MySQL [(none)]> show slave status for channel 'primary'\G
You should check for Slave_SQL_Running: Yes and Seconds_Behind_Master should be a number. This may be zero, or it may be indicating that replication is currently lagged, which is fine, as it will need to catch up with anything that's changed since we did the initial replication.
Beginning the streaming replication (secondary back to primary)
We now want to set up the replication in reverse so that any changes made on the secondary are replicated back to the primary and the rest of the cluster. This process is very similar to above.
First, obtain the MASTER_LOG_FILE and MASTER_LOG_POS. In this case they are obtained from the secondary.
secondary-server:~$ mysql -u root -p
MariaDB/MySQL [(none)]> SHOW MASTER STATUS;
The output should show a file and position similar to the following.
+--------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+--------------------+----------+--------------+------------------+
| log-bin.003541 | 370 | | |
+--------------------+----------+--------------+------------------+
Now we go to the primary and begin the replication using this data. Again, be sure to fill in all values correctly, using the MASTER_LOG_FILE and MASTER_LOG_POS obtained from the the command above which we can on the new secondary. MASTER_HOST should be the IP of the secondary this time. The repslave user will already exist on the secondary as it will have come across during the initial data replication.
MariaDB
primary-server:~$ mysql -u root -p
MariaDB [(none)]> CHANGE MASTER 'secondary_1' TO MASTER_HOST='XXXXXX', MASTER_USER='repslave', MASTER_PASSWORD='XXXXXX', MASTER_LOG_FILE='XXXXXX', MASTER_LOG_POS=XXX;
MariaDB [(none)]> start slave 'secondary_1';
MySQL
primary-server:~$ mysql -u root -p
MySQL [(none)]> CHANGE MASTER 'secondary_1' TO MASTER_HOST='XXXXXX', MASTER_USER='repslave', MASTER_PASSWORD='XXXXXX', MASTER_LOG_FILE='XXXXXX', MASTER_LOG_POS=XXX FOR CHANNEL 'secondary_1';
MySQL [(none)]> start slave FOR CHANNEL 'secondary_1';
We should now have bi-directional replication between the primary and our new secondary. As before, the status can be verified using the following command:
MariaDB
MariaDB [(none)]> show slave 'secondary_1' status\G
MySQL
MySQL [(none)]> show slave status FOR CHANNEL 'secondary_1'\G
More Servers
All the steps above, starting with "Prepare a secondary server" can be repeated to create another secondary, up to a maximum determined by the number we chose for auto_increment_increment at the start. For example with auto_increment_increment = 3 we can have 2 secondary servers. All secondary servers must connect back to the same primary server (the one where log_slave_updates is enabled).
Now we have a cluster
By setting up bi-directional replication, we now have a number of database servers containing the same data. Any writes made to one server will be streamed to all other servers in the cluster. If one server becomes unavailable, applications are able to simply connect to another server and continue to serve requests. MariaDB's replication is resilient against network problems, and will automatically reconnect as quickly as possible after any outage.
Automatic Failover
we use 2 servers in our primary data centre, and we want the second one to take over automatically if anything happens to the first. This is achieved using a virtual IP address and the keepalived tool. This ensures that the virtual address is only configured on one server, and if that server fails, it automatically configures the address on the backup server. A simple keepalived configuration looks like the following. It should be identical on both servers, apart from the priority, which should be higher on the primary server. Note that both servers should be defined as state BACKUP. One will become active after a negotiation.
vrrp_instance CODEBASE-DB-VIP {
state BACKUP
interface eth0
virtual_router_id 10
priority 100
authentication {
auth_type PASS
auth_pass GENERATE_A_PASSWORD_HERE
}
virtual_ipaddress {
192.0.2.10/24
}
}
Monitoring
It's very important that we ensure that the replication is running at all times. On each server the following query can be run to show the status of its replication:
MariaDB
MariaDB [(none)]> show all slaves status\G
MySQL
MySQL [(none)]> show slave status\G
The output will contain a lot of data, but we are mostly interested in the Slave_SQL_Running and Seconds_Behind_Master columns for each connection. Each secondary will have one connection, named 'primary', whereas the primary will have a status for each secondary it is replicating from. It is strongly advised that a monitoring tool be used to generate alerts if the replication stops, or becomes too lagged.
Conclusion
In this post, we've covered the full process of how we are able to configure a redundant cluster of MariaDB servers, providing both failover, and offsite replication of data. This provides an excellent level of protection against hardware failure, and by using an off-site server, we can even continue to access our data in the event of a whole data centre being offline.
This setup has proven extremely useful in providing database resilience and keeping all our applications online in the inevitable event of hardware failures.